As above, so below: Bare metal Rust generics 1/2
I've had the pleasure to work with very experienced firmware developers; the kind of people who know the size of their red zones and routinely transform coffee into linker scripts and pointer dereferences. In other words, the Mels and Zeus Hammers of the world.
When it comes to the tools of our trade, many of them are curious and experimental. Some of them—very much myself included—explore far enough to leave pragmatism behind and veer into idealism, stubbornly forcing beautiful round pegs into industrial square holes. Hey, maybe they're square for a reason, but it doesn't hurt to try.
The majority of them aren't like that. Your average battle-tested firmware developer has accrued a healthy distrust of the abstract, probably born of watching shiny platonic constructs crash and burn with painfully real and concrete error traces. It is sobering, having to chase a hardfault on a tiny MCU across enough vtables and templated code to make Herb Sutter puke angle brackets. No wonder modern approaches are met with some resistance unless the LOADs and the STOREs are in clear view.
I felt this way too when someone suggested to me, back in 2014, that an up-and-coming language called Rust showed promise in the embedded field. Surely not, I thought, too high level. Even though I had been playing with it already, my profoundly ingrained bit-twiddling instincts told me not to trust a language that supported functional programming, or one that dared to have an opinion on how I managed my memory. Bah! That's how you get philosophers to run out of forks, and your forks to turn into SIGSEGVs.
I was wrong.
Through the past five years of experimentation, I've gone from intrigued, to optimistic, to convinced that Rust is an ideal language to build industrial grade, bulletproof bare metal software. Beyond that, I've come to realize that even the highest level constructs that the base language offers are applicable to firmware development, very much unlike other languages that span a wide range of paradigms (I'm looking at you, C++). There are a few reasons I felt this way:
- Rust's safety guarantees and general strictness bring the debug time down significantly, so there's less need to spend time developing mental maps of how high level constructs correspond to hardware primitives.
- The type system is great at enforcing local reasoning and preventing leaky abstractions. Building decoupled systems with no runtime cost is easy.
- The compiler error messages are worthy of an AI assistant with concerning mind-reading abilities.
Lately, I've had the chance to work on a Rust
STM32F412
project in a professional setting, with one of the goals being to foster a Rust
knowledge pool at my company. The project, Loadstone, is a 32kb secure
bootloader targeting bare metal devices for the medical industry.
While it would've been easier—and much less of a headache to my colleagues—to
stick to a subset of Rust more familiar to C developers, with your fors, your
*mut u8s and your unsafes, I instead decided not to pull any punches and
make liberal use of generics, iterator adapters, typestate programming and other
stuff that would've made 2010's cuervo cry blood and hug the closest copy of
Kernighan and Ritchie.
The pressures of a real collaborative project have taught me a lot, and many assumptions have been refined thanks to the criticism of several skilled outsiders who, as outsiders often do, had a privileged view on things I took for granted.
A topic that came up frequently in code review is generics. Perhaps still recovering from a SFINAE nightmare, some colleagues were unsure about the use of generics to group behaviour that we'd normally write separate implementations for. The concerns tended to fall in one of three categories:
- Runtime performance.
- Binary size bloat.
- Habitability and readability.
The first is easy to dispel, as it often comes from unfamiliarity with static dispatch. No vtables or heap allocations in anything we're doing, promise! The second concern is valid but I've found it to be negligible in practice; I have plans for another blog post giving some concrete benchmarks.
The last concern is the most subjective and thus the hardest to argue, so I decided to focus on it in this blog series. I'll go over the design process of two similar flash memory drivers, and hopefully show how generic programming can make the job easier and the result more habitable, even in the barren, heapless, rugged world of bare metal firmware.
Compile times are another common—and very valid—argument against liberal use of generics. However, it is not a big problem for low footprint embedded projects like this one.
What is Flash Memory?🔗
Flash memory is electronic
non-volatile storage. It's ubiquitous in consumer electronics; any time you
switch a small device off and it remembers something—whether it's settings,
songs, documents, even its own program—chances are you have flash memory to
thank. We'll be looking at two different NOR flash chips, since the first demo
port of Loadstone requires us to operate both:
- The embedded STM32F412 1MB MCU flash.
- The external 128MB Micron N25Q128 flash chip present in the STM32F412ZGT6 Discovery Kit
You probably knew what flash memory is used for already, but what non-firmware
developers may not know is that flash memory is quirky. You cannot simply
write a byte to a NOR flash address, sir, that would be rude. While a blob of
flash memory will happily turn a 1 into a 0, the opposite operation will
fail silently.
You can think of every 1 bit (NOR flash's erased state) as a lit candle you
can blow out. However, in this metaphor you don't get a lighter
to light them back up; you get a flamethrower. Without getting into the hardware
principles involved, the design of NOR flash memory requires that you erase
(i.e. set to 1) memory in bulk, in chunks often orders of magnitude bigger
than the minimum addressable memory. On most chips you even have a three way
mismatch: your read, write and erase sizes aren't equal. Ugh.
As you can imagine, this makes writing flash drivers a bit of a pain, particularly because even the smallest write operations turn into read/write cycles. Writing a single byte requires reading the minimum erasable block surrounding the targeted address (which may itself require multiple reads), potentially erasing the entire block, then writing back the original data merged with the desired byte.
As you can also imagine, nobody but the person writing this driver wants to care about this. Even in the minimalistic world of bare metal software, productive collaboration depends on developers filing away these sharp edges, presenting interfaces that uniformize or hide any aspects of hardware irrelevant to the bigger design. As such, a first stab at a flash memory interface should simply offer a way to read and write ranges of memory.
Let's look at some code:
pub trait ReadWrite {
type Error;
type Address;
fn read(&mut self, address: Self::Address, bytes: &mut [u8]) -> Result<(), Self::Error>;
fn write(&mut self, address: Self::Address, bytes: &[u8]) -> Result<(), Self::Error>;
fn range(&self) -> (Self::Address, Self::Address);
fn erase(&mut self) -> Result<(), Self::Error>;
}
The above is what I converged on as a generic interface to a flash
driver. If you're unfamiliar with Rust generics, the above isn't a type, or a
parent class to inherit from. It's more like a Haskell typeclass; a set of
requirements for a concrete type to implement, described in this case in the
form of associated types (Error and Address) and method signatures (read,
write, range and erase).
Even at this early step, some tradeoffs have to be made. The keen,
hardfault-traumatized reader will notice that this interface doesn't lend itself
well to timing sensitive problems. All methods are blocking, and abstracting the
read/write cycle away will naturally lead to non-deterministic write times; a
write may take very little if it only requires toggling bits off, or it might
take very long if it straddles two big sectors requiring erase operations. The
bytes output parameter in read might also strike you as not too rusty, where
returning a Vec<u8> is often idiomatic. Unfortunately we have no heap to work
with, so if you want to take your bytes home you'll have to bring your own bag.
Indeed, it's hard to write the universal interface. This one made sense for the problems we're solving, but make sure to keep in mind the requirements of your project!
Why not simply write a concrete type?🔗
Ah, the word "simply" is tricky. Datasheet in hand, it may have been easier to write. It might even save us a few bytes down the line. But altogether I think the benefits of starting here are well worth the drawbacks:
- Makes it easy to write test doubles and leverage static dispatch for unit testing. This kind of approach is what I miss the most when writing C, where I'm forced to resort to link time substitution or to do things with the preprocessor too vile to even mention here.
- Decouples your design from the get go and makes collaboration easy. Another developer can immediately start working against this interface, and it's abstract enough to give you confidence it won't need to be changed as more knowledge of the hardware emerges.
- Going abstract first forces you to think long and hard about what behaviour is common to each implementation and what behaviour isn't, which helps to not repeat yourself.
But the biggest reason, and one where C++ and Rust diverge, is the fact that you can reason about this interface locally. This stems from a non-obvious difference between the C++ template system and Rust traits. Where C++ templates type check at the point of instantiation, Rust traits type check at the point of definition.
What does this mean? It means that the inscrutable, seven-feet-deep-in-a-library C++ template errors are impossible in Rust, because the compiler doesn't need to go beyond the interface to prove it is used correctly.
A similar interface using C++ templates could send two developers on separate paths, one working on a concrete flash driver implementation, and another on a higher level structure that relies on flash memory, only for the walls between them to come crashing down when a subtle incompatibility creeps up on either side, leaking details of one developer's work into the other's error messages. Rust's walls here are, in contrast, solid.
Yes, I'm aware that C++20 concepts and constraints help encode some of these requirements and make errors nicer. Unfortunately they can't enforce all behaviour to be constrained, so the C++ template system remains duck typed. If your duck doesn't quack, you get angle bracket error soup.
Descending into the concrete world🔗
Now that we're happy with our interface, it's time to roll up our sleeves and go datasheet diving. We'll start with the stm32f412 MCU reference. First thing we want to know are our write, read and erase sizes. Thankfully, we find it front and center at the start of section 3.3.

Okay, so our minimum write is one byte, our maximum read is four 32 bit words, and our minimum erase is a (so far undefined) sector. Next step is to find the memory map, to work out what a sector is, as well as its size.
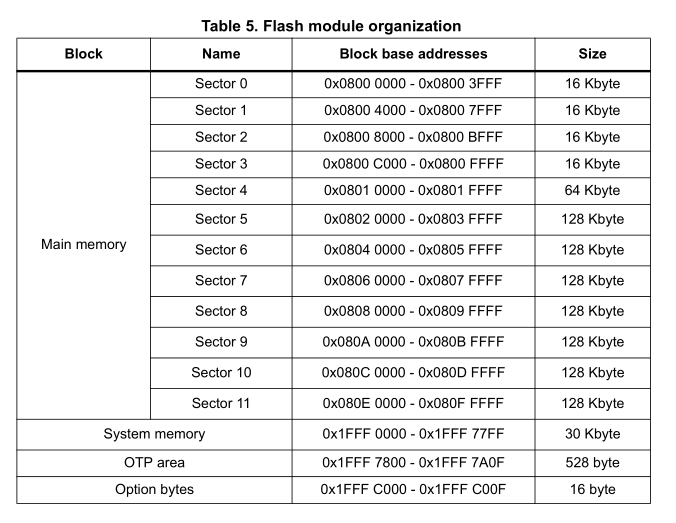
As you can see, we have somewhat lopsided sector sizes. This is common in MCU flash chips, where you're likely to store smaller amounts of miscellaneous data. There are three special purpose sectors at the end we don't care about. We know enough to start laying the groundwork of our driver:
#[derive(Default, Copy, Clone, Debug, PartialOrd, PartialEq, Ord, Eq)]
pub struct Address(pub u32);
pub struct McuFlash {
stm32f4::stm32f412::FLASH,
}
#[derive(Copy, Clone, Debug, PartialEq)]
pub enum Block {
Main,
SystemMemory,
OneTimeProgrammable,
OptionBytes,
}
#[derive(Copy, Clone, Debug, PartialEq)]
struct Sector {
block: Block,
location: Address,
size: usize,
}
const NUMBER_OF_SECTORS: usize = 15;
pub struct MemoryMap {
sectors: [Sector; NUMBER_OF_SECTORS],
}
const MEMORY_MAP: MemoryMap = MemoryMap {
sectors: [
Sector::new(Block::Main, Address(0x0800_0000), KB!(16)),
Sector::new(Block::Main, Address(0x0800_4000), KB!(16)),
Sector::new(Block::Main, Address(0x0800_8000), KB!(16)),
Sector::new(Block::Main, Address(0x0800_C000), KB!(16)),
Sector::new(Block::Main, Address(0x0801_0000), KB!(64)),
Sector::new(Block::Main, Address(0x0802_0000), KB!(128)),
Sector::new(Block::Main, Address(0x0804_0000), KB!(128)),
Sector::new(Block::Main, Address(0x0806_0000), KB!(128)),
Sector::new(Block::Main, Address(0x0808_0000), KB!(128)),
Sector::new(Block::Main, Address(0x080A_0000), KB!(128)),
Sector::new(Block::Main, Address(0x080C_0000), KB!(128)),
Sector::new(Block::Main, Address(0x080E_0000), KB!(128)),
Sector::new(Block::SystemMemory, Address(0x1FFF_0000), KB!(32)),
Sector::new(Block::OneTimeProgrammable, Address(0x1FFF_7800), 528),
Sector::new(Block::OptionBytes, Address(0x1FFF_C000), 16),
],
};
A few notes:
KBis just a tiny helper macro that multiplies by 1024.- The FLASH type inside our McuFlash struct is part of the svd2rust-generated Peripheral Access Crate.
- While it would've been more correct to say that blocks contain sectors, we define blocks as a property of sectors as there isn't much use for them beyond classifying the sector type.
constmarks theMEMORY_MAPstruct as a compile time construct. This means the compiler is free to inline it or place in static memory based on your optimization criteria, and it becomes available in constant expressions.
Now we hit a fork in the road. My usual instinct would be to fully develop and test this driver, and then move on to the next one. However, we're experimenting with an abstraction-first approach, so let's take an early detour and take our external Micron driver to a similar spot.
Generics aren't only useful at the interface level! Private behaviour internal to your library can also benefit. For this project, it paid off to be proactive and spot possible sources of duplication early.
Measuring the external flash🔗
Here's what the Micron N25Q128 technical documentation has to say:

Okay, so far so good. For our current purposes, we can ignore the sector granularity and consider 4kb our minimal erase size. Looking around the reference, we find that there's no maximum read size, but our writes are limited to one page at a time:

All that's left then is to look at the memory map:
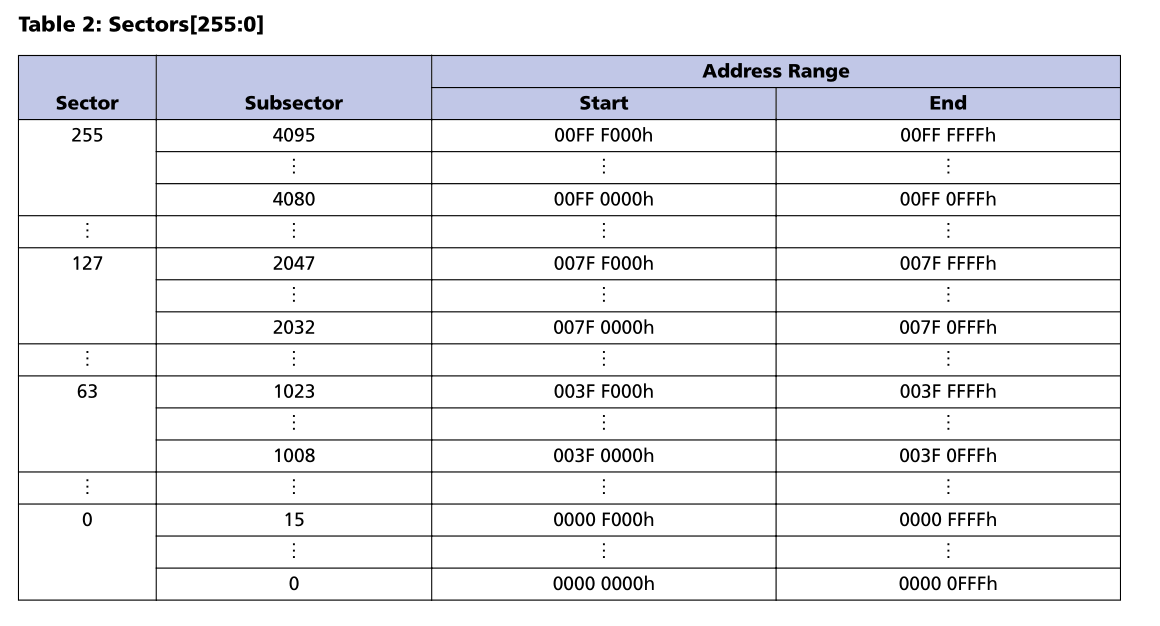
That's... Wow. That's a lot of sectors.
We can immediately see how the approach we used for the MCU flash is not going to work; we can't simply inline 256 sectors in a table. There's also a lot more structure to this one—sectors and subsectors are evenly spaced—which lends itself to a programmatic representation.
There are a few ways we can encode this. I tried to define the array using a constant expression at first, but the limited expressiveness of constant expressions at this time made the code a bit inelegant. Instead, I settled on an iterator solution:
#[derive(Default, Copy, Clone, Debug, PartialOrd, PartialEq, Eq, Ord)]
pub struct Address(pub u32);
pub struct MemoryMap {}
pub struct Sector(usize);
pub struct Subsector(usize);
pub struct Page(usize);
const BASE_ADDRESS: Address = Address(0x0000_0000);
const PAGES_PER_SUBSECTOR: usize = 16;
const SUBSECTORS_PER_SECTOR: usize = 16;
const PAGES_PER_SECTOR: usize = PAGES_PER_SUBSECTOR * SUBSECTORS_PER_SECTOR;
const PAGE_SIZE: usize = 256;
const SUBSECTOR_SIZE: usize = PAGE_SIZE * PAGES_PER_SUBSECTOR;
const SECTOR_SIZE: usize = SUBSECTOR_SIZE * SUBSECTORS_PER_SECTOR;
const MEMORY_SIZE: usize = NUMBER_OF_SECTORS * SECTOR_SIZE;
const NUMBER_OF_SECTORS: usize = 256;
const NUMBER_OF_SUBSECTORS: usize = NUMBER_OF_SECTORS * SUBSECTORS_PER_SECTOR;
const NUMBER_OF_PAGES: usize = NUMBER_OF_SUBSECTORS * PAGES_PER_SUBSECTOR;
impl MemoryMap {
pub fn sectors() -> impl Iterator<Item = Sector> {
(0..NUMBER_OF_SECTORS).map(Sector)
}
pub fn subsectors() -> impl Iterator<Item = Subsector> {
(0..NUMBER_OF_SUBSECTORS).map(Subsector)
}
pub fn pages() -> impl Iterator<Item = Page> {
(0..NUMBER_OF_PAGES).map(Page)
}
pub const fn location() -> Address { BASE_ADDRESS }
pub const fn end() -> Address { Address(BASE_ADDRESS.0 + MEMORY_SIZE as u32) }
pub const fn size() -> usize { MEMORY_SIZE }
}
impl Sector {
pub fn subsectors(&self) -> impl Iterator<Item = Subsector> {
((self.0 * SUBSECTORS_PER_SECTOR)..((1 + self.0) * SUBSECTORS_PER_SECTOR)).map(Subsector)
}
pub fn pages(&self) -> impl Iterator<Item = Page> {
((self.0 * PAGES_PER_SECTOR)..((1 + self.0) * PAGES_PER_SECTOR)).map(Page)
}
pub fn location(&self) -> Address { BASE_ADDRESS + self.0 * Self::size() }
pub fn end(&self) -> Address { self.location() + Self::size() }
pub fn at(address: Address) -> Option<Self> {
MemoryMap::sectors().find(|s| s.contains(address))
}
pub const fn size() -> usize { SECTOR_SIZE }
}
// [..] Similar implementations for subsector and page
Again, a few notes:
- Existential types as make the signature clearer, as nobody consuming this function cares about the iterator adapters used internally.
- Iterator syntax makes it very easy to express memory location conditions, e.g.
memory_map.sectors().nth(5)?.pages().find(|p| p.contains(address)) - I like to think that at some point in the far future when we have Rust-powered
flying cars, we'll be able to make all the functions you see under the
MemoryMapimplementationconst. Unfortunately iterators aren't fair game inconst fnyet, let alone existential types.
Taking a step back🔗
It seems like we aren't doing well in our quest to develop both drivers in parallel. We've barely started and we already have two fundamentally different memory map representations. Besides, erase granularities are also different; the MCU flash erases by sector while the Micron chip is happy to go down to subsectors.
Should we give up, and buckle up for two fully separate driver implementations? I say we don't. Here's where Rust comes in, giving us amazing tools to step back and focus on what actually matters. Let's forget all the specific chip details we've learned and sketch out the abstract details of what we're working with.
- We have
some concept of an address. - We have
some concept of a region, whichcontains addresses. This can be a sector, a subsector, or a page. The distinction is arbitrary so it doesn't matter to us.
Okay, that looks a lot simpler. Let's model it somewhere private in our crate where we store functionality common to our flash drivers:
pub trait Address: Ord + Copy {}
pub trait Region<A: Address> {
fn contains(&self, address: A) -> bool;
}
The beautiful thing is that the representation above doesn't lose any
generality. Even though we have already committed to certain interpretations of
what a Region is, and even though these representations behave very
differently, we know they both conceptually conform to the traits above so we can
safely use them as our only model going forward.
In the next entry, we'll see how a representation as simple as this is enough for us to write a lot of useful code, so that each final concrete driver becomes a succinct representation of the specifics of the hardware, with most actual behaviour living in the abstract layer common to both of them.
Thanks for reading🔗
I'm not very active on social media, so send any questions, suggestions, criticism or hate mail at my e-mail, or the post's reddit thread.
Happy rusting!